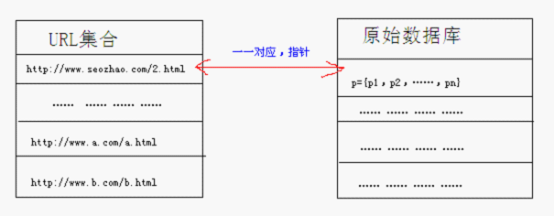
搜索引擎最重要的是什么?有人会说是查询结果的准确性,有人会说是查询结果的丰富性,但其实这些都不是搜索引擎最最致命的地方。对于搜索引擎来说, 最最致命的是查询时间。试想一下,如果你在百度界面上查询一个关键词,结果需要5分钟才能将你的查询结果反馈给你,那结果必然是你很快的舍弃掉百度。 搜索引擎为了满足对速度苛刻的要求(现在商业的搜索引擎的查询时间单位都是微秒数量级的),所以采用缓存支持查询需求的方式,也就是说我们在查询搜索时所得到的结果并不是及时的,而是在其服务器已经缓存好了的结果。那么搜索引擎工作的大体流程是什么样子呢?我们可以理解为三段式。 本文仅仅是对着三段工作流程进行大体上的讲解与综述,其中一些详细的技术细节将会用其它的文章进行单独的讲解。 一.网页搜集 网页搜集,其实就是大家常说的蜘蛛抓取网页。那么对于蜘蛛(google称之为机器人)来说,他们感兴趣的页面分为三类: 1.蜘蛛从未抓去过的新页面。 2.蜘蛛抓取过,但页面内容有改动的页面。 3.蜘蛛抓取过,但现在已删除了的页面。 那么如何行之有效的发现这三类页面并进行抓取,就是spider程序设计的初衷与目的。那么这里就涉及到一个问题,蜘蛛抓取的起始点。 每一位站长只要你的网站没有被严重降权,那么通过网站后台的服务器,你都可以发现勤劳的蜘蛛光顾你的站点,但是你们有没有想过从编写程序的角度上来 说,蜘蛛是怎么来的呢?针对于此,各方有各方的观点。有一种说法,说蜘蛛的抓取是从种子站(或叫高权重站),依照权重由高至低逐层出发的。另一种说法蜘蛛 爬在URL集合中是没有明显先后顺序的,搜索引擎会根据你网站内容更新的规律,自动计算出何时是爬取你网站的最佳时机,然后进行抓取。 其实对于不同的搜索引擎,其抓取出发点定然会有所区别,针对于百度,笔者较为倾向于后者。在百度官方博客发布的《索引页链接补全机制的一种办法》一文中,其明确指出“spider会尽量探测网页的发布周期,以合理的频率来检查网页”,由此我们可以推断,在百度的索引库中,针对每个URL集合,其都计算出适合其的抓取时间以及一系列参数,然后对相应站点进行抓取。 在这里,我要说明一下,就是针对百度来说,site的数值并非是蜘蛛已抓取你页面的数值。比如site:,所得出的数值并 不是大家常说的百度收录数值,想查询具体的百度收录量应该在百度提供的站长工具里查询索引数量。那么site是什么?这个我会在今后的文章中为大家讲解。 那么蜘蛛如何发现新链接呢?其依靠的就是超链接。我们可以把所有的互联网看成一个有向集合的聚集体,蜘蛛由起始的URL集合A沿着网页中超链接开始 不停的发现新页面。在这个过程中,每发现新的URL都会与集合A中已存的进行比对,若是新的URL,则加入集合A中,若是已在集合A中存在,则丢弃掉。蜘 蛛对一个站点的遍历抓取策略分为两种,一种是深度优先,另一种就是宽度优先。但是如果是百度这类商业搜索引擎,其遍历策略则可能是某种更加复杂的规则,例 如涉及到域名本身的权重系数、涉及到百度本身服务器矩阵分布等。 二.预处理 预处理是搜索引擎最复杂的部分,基本上大部分排名算法都是在预处理这个环节生效。那么搜索引擎在预处理这个环节,针对数据主要进行以下几步处理: 1.提取关键词 蜘蛛抓取到的页面与我们在浏览器中查看的源码是一样的,通常代码杂乱无章,而且其中还有很多与页面主要内容是无关的。由此,搜索引擎需要做三件事 情:1代码去噪。去除掉网页中所有的代码,仅剩下文本文字。②去除非正文关键词。例如页面上的导航栏以及其它不同页面共享的公共区域的关键词。③去除停 用词。停用词是指没有具体意义的词汇,例如“的”“在”等。 当搜索引擎得到这篇网页的关键词后,会用自身的分词系统,将此文分成一个分词列表,然后储存在数据库中,并与此文的URL进行一一对应。下面我举例说明。 假如蜘蛛爬取的页面的URL是****.com/2.html,而搜索引擎在此页面经过上述操作后提取到的关键词集合为p,且p是由关键词p1,p2,……,pn组成,则在百度数据库中,其相互间的关系是一一对应,如下图。
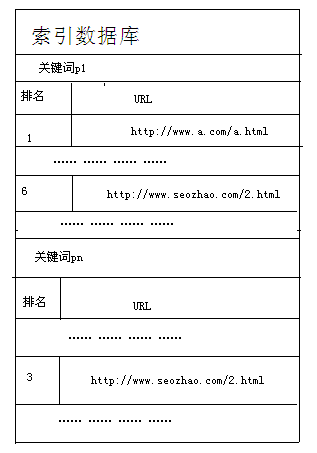
2.消除重复与转载网页 每个搜索引擎其识别重复页面的算法均不相同,但是其中笔者认为,如果将消重算法理解为由100个元素组成,那么所有的搜索引擎恐怕其80个元素都是 完全一样的。而另外20个元素,则是根据不同的搜索引擎针对seo的态度不同,而专门设立的对应策略。本文仅对搜索引擎大体流程进行初步讲解,具体数学模 型不多做讲解。 3.重要信息分析 在进行代码除噪的过程中,搜索引擎并非简单的将其去除掉而已,而是充分利用网页代码(例如H标签、strong标签)、关键词密度、内链锚文本等方式分析出此网页中最重要的词组。 4.网页重要度分析 通过指向该网页的外链锚文本所传递的权重数值,来为此网页确定一个权重数值,同时结合上述的“重要信息分析”,从而确立此网页的关键词集合p中每一个关键词所具备的排名系数。 5.倒排文件 正如上文所说,用户在查询时所得到的查询结果并非是及时的,而是在搜索引擎的缓存区已经大体排好的,当然搜索引擎不会未卜先知,他不会知道用户会查 询哪些关键词,但是他可以建立一个关键词词库,而当其处理用户查询请求的时候,会将其请求按照词库进行分词。那么这样下来,搜索引擎就可以在用户产生查询 行为之前,将词库中的每一个关键词其对应的URL排名先行计算好,这样就大大节省了处理查询的时间了。 简单来说,搜索引擎用控制器来控制蜘蛛爬取,然后将URL集与原始数据库进行保存,保存之后再用索引器控制每个关键词与URL之间的对应关系,并将其保存在索引数据库中。 下面我们来举例说明: 假若****.com/2.html页面被切词成p={p1,p2,p3,……,pn},则其在索引数据库中由下图方式体现。
|